
Zukünftige Energiesysteme zeichnen sich durch eine enge Verflechtung zwischen dem elektrischen System und der Informations- und Kommunikationstechnologie für die Steuerung des Stromnetzes aus. Die zunehmende Flexibilisierung von Erzeugung und Verbrauch bedingt Automatisierung und Datenaustausch. Meist werden für den Datenaustausch Lösungen benötigt, die Informationen zuverlässig und zeitgerecht an ihr Ziel bringen. Dazu dienen Messaging Middleware Lösungen. Häufig werden diese in Projekten von Grund auf neu entwickelt und auf diese Weise das Rad immer wieder neu erfunden. WissenschaftlerInnen von Salzburg Research haben deshalb ein wiederverwendbares und einfach nutzbares Messaging System für Smart Grids entworfen, welches eine robuste und skalierbare Nachrichtenübermittlung für eine Vielzahl von Anwendungen im Energiesystem ermöglicht.
Der Austausch von Nachrichten ist eine zentrale Funktion in Smart Grids. Häufig werden Lösungen für den Datenaustausch in Forschungs- und Entwicklungsprojekten jedoch spezifisch für das Projekt entwickelt. Dies ist eine zeitraubende Aufgabe und besonders nachteilig wenn man bedenkt, dass die Datenübertragung in Smart Grid Projekten eher Mittel zum Zweck ist als eigentlicher Kern der Entwicklung ist. Aus diesem Grund kann eine einfach zu implementierende und wiederverwendbare Messaging-Lösung als wertvoller Beitrag zur Smart Grid-Forschung angesehen werden. In diesem Beitrag stellen wir eine von Salzburg Research entwickelte nachrichtenorientierte Middleware (MOM) vor, die die typischen Anforderungen von Anwendungen in Energieumfeld wie Robustheit, Zuverlässigkeit, Skalierbarkeit und Sicherheit erfüllt. All dies ohne auf Benutzerfreundlichkeit, einfache Bereitstellung sowie die Anwendbarkeit in unterschiedlichsten Anwendungsszenarien zu verzichten. So ist eine Anwendungsprogrammierschnittstelle (API) Teil des Systems, die sich leicht verwenden und in Softwarekomponenten der Anwendung integrieren lässt.
Allgemein bieten MOM-Lösungen Vorteile durch die Unterstützung unterschiedlicher Varianten für den Datenaustausch wie beispielsweise Gruppenkommunikation oder Entkopplung der kommunizierenden Komponenten (so erhalten z.B. auch Komponenten, die zum Zeitpunkt des Nachrichtenversands gerade offline sind, die Daten, sobald sie wieder online sind). Moderne Lösungen sind darüber hinaus hoch skalierbar und performant. Das heißt die Lösungen können eine große Anzahl an Komponenten bedienen und Verlangsamen die Verteilung der Daten kaum. Darüber hinaus besteht ein weiterer Vorteil darin, dass die MOM-Lösungen Kommunikation als Dienst für andere Komponenten anbieten können. Dadurch muss bei der Entwicklung dieser Komponenten keine Kommunikationslogik entworfen und implementiert werden, sondern die Entwicklungsarbeit kann auf die Kernfunktionen der Komponenten konzentriert werden. Die MOM bietet Sicherheit, Performanz, Skalierbarkeit, Zuverlässigkeit und Robustheit beim Austausch von Nachrichten als automatisch vorhandene Dienstleistung.
In diesem Beitrag wird die Anwendung der von Salzburg Research entwickelten Messaging-Lösung im Zusammenhang mit einem agentenbasierten System für den Flexibilitätshandel in Energiesystemen vorgestellt.
Smart Grid: Agenten-basierter Flexibilitätshandel
Die MOM-Lösung wird im Kontext einer Anwendung zur Orchestrierung von Energieverbrauchern und Erzeugungsanlagen beispielsweise Batterien, Photovoltaik und Industrielasten vorgestellt. Die Anlagen können ihre Produktion oder ihren Verbrauch entweder zeitlich verschieben oder mengenmäßig variieren. Diese Flexibilität der Anlagen wird an einem zentralen Markt gehandelt. Ziel des Marktes ist der optimale Einsatz der Flexibilitäten, um zu minimalen Kosten die Energiebilanz im Stromnetz auszugleichen, d. h. die Ausspeisung und die Einspeisung elektrischer Energie im Netz aneinander anzugleichen. Nach der marktbasierten Optimierung werden entsprechende Signale an die Betreiber der flexiblen Anlagen (Flexibilitätsanbieter) gesendet und in weiterer Folge die einzelnen Anlagen entsprechend angesteuert. Die Systemarchitektur ist als hierarchisches Multi-Agenten-System konzipiert. Auf jeder der vier logischen Architekturschichten agiert ein Agententyp mit bestimmten Aufgaben.
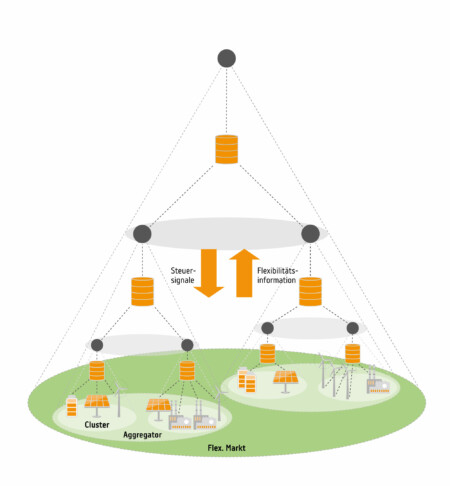
Abbildung 1 zeigt die geschichtete Agenten-Architektur. Im innersten Bereich befinden sich Anlagen inklusive der Anlagenagenten (nicht explizit dargestellt), die eine Schnittstelle der Anlagen (z. B. ein Photovoltaik-System oder eine Batterie) zum Flexibilitätshandelssystem bereitstellen. Zusätzlich implementieren Anlageagenten eine gerätespezifische Schnittstelle, um Statusinformationen (z. B. den Ladezustand einer Batterie) direkt aus dem Gerät auszulesen oder Steuerbefehle (z. B. Laden oder Entladen) an das Gerät zu senden.
Innerhalb der Hierarchie kann jeder Anlagenagent direkt mit genau einem Agenten des Clustering- oder Aggregationsbereichs verbunden sein. Beide dienen dem Zweck der Aggregation von Flexibilitätspotenzialen der einzelnen Anlagen. Der Unterschied zwischen beiden Bereichen besteht darin, dass die Cluster-Agenten logisch zusammengehörige Assets gruppieren (z. B. die sich in einer Anlage befinden), während Aggregator-Agenten ganze Cluster oder einzelne Assets aufgrund direkter vertraglicher Beziehungen gruppieren. Aggregator-Agenten handeln im Auftrag von Anlageneigentümern mit Flexibilitäten am Markt.
Auf dem Flexibilitätsmarkt werden marktbasiert die Angebote der Aggregatoren ausgwählt, so dass das gesamte Flexibilitätspotenzial optimal eingesetzt werden kann, um einen stabilen Netzbetrieb ohne Engpässe zu gewährleisten.
Allgemein fließen Flexibilitätsinformationen in Form von Gerätezuständen oder Flexibilitätsgeboten von den Anlageagenten über die verschiedenen Bereiche zum Marktbereich (upstream). In der entgegengesetzten Richtung (downstream) werden Steuersignale für die Flexibilitätsplanung und -aktivierung übertragen.
Die Middleware-Instanzen sind in einer hierarchischen Systemarchitektur angeordnet, welche die Bereiche der Agentenarchitektur abbildet. Die Instanzen kümmern sich um die Kommunikation eines Bereichs mit seinem umgebenden Bereich. So ist eine Middleware-Instanz für den Datenaustausch zwischen dem Anlagenbereich und dem Clustering-Bereich zuständig, eine weitere für den Datenaustausch zwischen Clustering-Bereich und Aggregationsbereich usw. Die einzelnen Instanzen werden vom Betreiber des übergeordneten Bereichs bereitgestellt und verwaltet. Das heißt konkret, dass Middleware-Instanzen von den Cluster-Betreibern, den Aggregatoren und dem Betreiber der Marktplattform betrieben und individuell konfiguriert werden. Dieser Ansatz berücksichtigt auch Sicherheit, Robustheit und Skalierbarkeit des Systems. Dies ergibt sich daraus, dass die Middleware-Betreiber jedes Bereichs über ein genaues Wissen über die angeschlossenen Agenten, z. B. durch genaue Kenntnis der Anlagentypen (z. B. für Cluster-Besitzer) oder der vertraglichen Beziehungen im Markt- und Aggregationsbereich besitzen. Darüber hinaus ist die Anzahl der angeschlossenen Agenten bei jeder Instanz im Vergleich zu einer zentralisierten Lösung auf eine verhältnismäßig kleine Anzahl beschränkt. Beide Aspekte sind besonders wichtig für groß skalierte Flexibilitätshandelssysteme, bei denen ggf. auch Tausende von Agenten am Flexibilitätshandel beteiligt sein können.
Kafka-basierte Nachrichtenvermittlung
Das in der vorgeschlagenen Messaging-Lösung implementierte MOM basiert auf Apache Kafka. Apache Kafka wurde deshalb als Ausgangspunkt für die Messaging-Lösung verwendet, da eine Reihe technischer Merkmale Kafka für eine skalierbare, robuste und sichere Lösung geeignet erscheinen lassen.
Apache Kafka ist als eine verteilte, brokerbasierte Streaming-Plattform konzipiert. Streaming meint in diesem Fall nicht nur Audio- oder Videodaten, sondern bezieht sich auf fortlaufende Datenströme aller Art. Das Ziel von Kafka ist es dabei, hochperformante Verarbeitung einer kontinuierlichen Abfolge von Eingabedaten (Datenpaketen) zu bieten. Die wichtigsten Entwurfsziele sind zuverlässiger Datentransfer, schnelle Verarbeitung, Skalierbarkeit und Fehlertoleranz. Dies sind wichtige Merkmale für eine Smart Grid-Messaging-Lösung im Hinblick auf potenziell viele beteiligte Systeme und die allgemeine Kritikalität solcher Systeme.
Grob gesagt hat Kafka die Aufgabe, Datenströme einer Datenquelle an einen oder mehrere Datenkonsumenten weiterzuleiten. Die wesentliche Komponente ist dazu der Kafka Messagebroker. Dieser empfängt den Datenstrom einer Quelle und speichert diesen zwischen, bis die Datenkonsumenten den Datenstrom abgerufen haben. Der Datenstrom selbst wird in einzelne Kafka-Nachrichten umgewandelt, die im Wesentlichen aus einem Schlüssel/Wertpaar für die Informationskodierung, einem Zeitstempel und einer Nachrichtenkategorisierung bestehen. Die Nachrichtenkategorie dient dazu logisch zusammengehörende Nachrichten (z. B. Aufgrund der Zugehörigkeit zu einem Anwendungsfall) einheitlich behandeln zu können. Die Nachrichtenkategorie wird üblicherweise schon bei der Erstellung der Nachricht durch die Datenquelle festgelegt. Kafka speichert alle zu einer Kategorie gehörigen Nachrichten in einem eigenen Nachrichtenpuffer (genannt Queue). Datenkonsumenten abonnieren Nachrichten unter Angabe der Kategorie beim Broker. Dabei kann jede Nachrichtenkategorie allgemein mehrere Konsumenten und Quellen haben (m:n Kommunikation). Der Broker ist für die Vermittlung der eingehenden Nachrichten verantwortlich. Er hat die Aufgabe, die Nachrichten im richtigen Nachrichtenpuffer abzulegen und darüber Buch zu führen, welche Nachrichten bereits von welchen Konsumenten abgerufen wurden.
Kafka garantiert die Skalierbarkeit des Systems dadurch, dass Nachrichten prinzipiell parallel auf mehreren Instanzen gespeichert werden und auch von dort abgerufen werden können. Dadurch können mehrere Nachrichtenquellen gleichzeitig Nachrichten einer Kategorie veröffentlichen aber auch mehrere Konsumenten gleichzeitig mit neuen Daten bedient werden. Auf den jeweiligen Instanzen behalten Nachrichten die Reihenfolge ihrer Veröffentlichung bei (First-in-first-out Reihenfolge). Auf welcher Instanz eines Nachrichtenpuffers eine Nachricht einsortiert wird, legt entweder die Datenquelle oder, falls die Datenquelle keine Instanz spezifiziert, das Kafka selbst fest. Für den Nachrichtenabruf fragt ein Konsument grundsätzlich ein Thema ab und ruft die Nachrichten einer beliebigen Partition ab. Um eine Möglichkeit des Lastausgleichs und der Parallelverarbeitung auf der Empfängerseite zu schaffen, können Verbraucher in Verbrauchergruppen organisiert werden, was zu einer direkten Zuordnung zwischen Verbrauchern innerhalb dieser Gruppe und bestimmten Partitionen führt: Jeder Verbraucher der Gruppe ruft die Nachrichten einer bestimmten Partition ab. Paralleles Lesen und Schreiben minimiert die zusätzliche Latenzzeit, die durch Nachrichtenvermittlung im Allgemeinen verursacht wird. Mit diesen Ansätzen konnte Kafka in Studien einen Durchsatz von 500 K Nachrichten/Sekunde erreichen.
Im Hinblick auf zuverlässige Datenübertragungen verwendet Kafka mehrere Ansätze. Erstens wird TCP für eine zuverlässige Nachrichtenübermittlung zwischen Datenquellen oder Konsumenten und dem Broker verwendet. Dies stellt sicher, dass Nachrichten während der Übertragung nicht verloren gehen. Darüber hinaus bietet Kafka die Garantie für die Nachrichtenzustellung, dass jede Nachricht einer Kategorie, von einem Empfänger mindestens einmalig abgerufen werden kann. Zur Buchführung, welche Nachricht an welchen Konsumenten nächstes ausgeliefert wird, verwaltet der Broker ein Lesezeichen für jeden Verbraucher. Dieses wird nur dann auf die nächste Nachricht gesetzt, wenn der Empfang der Nachricht vom Nachrichtenkonsumenten explizit bestätigt wurde.
Robustheit wird von Kafka ebenfalls durch die Redundanz der Nachrichtenpuffer auf verschiedenen Instanzen gewährleistet – im Unterschied zur vorgenannten Verteilung der Nachrichtenpuffer auf verschiedene Instanzen um parallele Zugriffe zu gewähren, handelt es sich bei dieser Replikation um direkte Abbilder eines Puffers auf einer anderen Instanz, auf die dort nicht von Quellen oder Konsumenten zugegriffen werden kann. Dies ist nötig, um die First-in-first-out Reihenfolge zu erhalten. Eines der Replikate wird als Leader betrachtet, wobei die Nachrichten zunächst dort gespeichert und anschließend auf andere Instanzen repliziert werden. Erst nachdem die Nachricht bei jeder Replikation auf der Festplatte gespeichert wurde, können abonnierte Verbraucher die Nachricht abrufen. Diese Nachrichtenpersistenz bietet auch ein Mittel zur Fehlertoleranz im Falle eines Systemausfalls einer Kafka-Instanz. Zusammen mit einer konfigurierbaren Aufbewahrungszeit, die angibt, wie lange Nachrichten im Kafka-System gespeichert werden, bietet dies auch ein Mittel zur Systemwiederherstellung für Nachrichtenkonsumenten. Falls Konsumenten ausfallen, haben diese nach dem Neustart die Möglichkeit, ihren internen Zustand nach einem Systemausfall wiederherzustellen, indem sie alte Nachrichten aus den jeweiligen Themenbereichen abrufen.
Im Hinblick auf die Sicherheit bietet Kafka zunächst TLS-gesicherte Verbindungen zwischen den Konsumenten/Produzenten und den Broker-Systemen sowie zusätzlich Zugriffskontrolllisten (ACLs), die die Zugriffsrechte (Lesen, Schreiben) angeben, die ein Konsument oder Produzent für jedes Thema hat. In der Lösung von Salzburg Research wurde zur Verbesserung der Sicherheit zusätzlich zu den TLS-gesicherten Verbindungen eine Erweiterung für echte Ende-zu-Ende-Verschlüsselung entwickelt. Diese ist weiter unten in diesem Artikel vorgestellt.
Konfiguration und Verwendung der MOM-Lösung
Zusätzlich wurde eine einfach zu bedienende Messaging-Middleware-Client-API für den Datentransfer zwischen den Agenten entwickelt. Diese reduziert den Integrationsaufwand für Entwickler von Softwarekomponenten auf ein minimales Maß. Derzeit ist die API für Java und Python verfügbar.
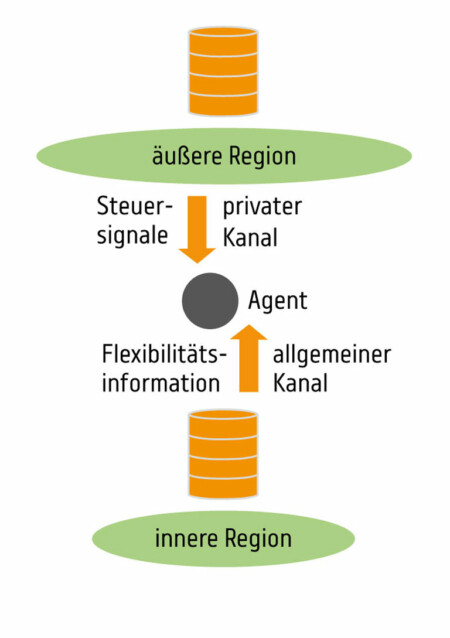
Die wichtigsten Designziele der Messaging-Client-API waren die Bereitstellung einer hochgradigen Abstraktion von Messaging-Details wie die Erstellung und Pflege der Verbindungen zwischen Agenten, die Topic- und Partitionsverwaltung, die Schlüsselverwaltung sowie die Nachrichtenverschlüsselung und -serialisierung. Dies ermöglicht es den Komponentenentwicklern, sich auf die Entwicklung der Kernlogik der Komponenten zu konzentrieren. Grundsätzlich ist die API für jede beliebige Topologie geeignet, in diesem Abschnitt zeigen wir den Aufbau der geschichteten Messaging-Hierarchie, wie sie für den geschilderten Anwendungsfall verwendet wird. Die entsprechende Konfiguration ist in Abbildung 2 dargestellt.
Im Wesentlichen verwendet jeder Agent einen allgemeinen Nachrichtenkanal für eingehende Flexibilitätsinformationen aus der inneren Region, sowie einen privaten Kanal für Kontrollinformationen der vom Broker der übergeordneten Region bereitgestellt wird. Die Kanäle sind dabei über Nachrichtenkategorien abgebildet. Dieser Ansatz wurde einerseits aus Gründen der Datensicherheit gewählt, aber auch, um die Anzahl der aktiven Verbindungen und damit die Kompelixität der Agenten zu minimieren (in diesem Fall maximal drei).
Bevor ein Agent Nachrichten senden oder empfangen kann, muss er beim Nachrichtenbroker registriert sein. Innerhalb der Messaging-Hierarchie verfügt jeder Agent über Verbindungen zu maximal zwei Brokern – ein Broker für Upstream-Datentransfers und/oder ein Broker für Downstream-Datentransfers. Die Messaging-API automatisiert die Verbindung der Agenten mit den Brokern weitestgehend. Dazu muss jedoch jede Verbindung, die ein Agent mit einem anderen Agenten hat, vorab konfiguriert werden. Ein Beispiel ist in Listing 1 zu sehen.
agent.id=cluster-1
connection.name=aggreCon
broker.address=192.168.100.135:9093
topic.in=cluster-1-in
security=TLS
Listing 1: Configuration file specifying settings for an agent connecting another agent
Neben einer eindeutigen Agenten-Kennung (agent.id) und einem Verbindungsnamen (connection.name) müssen auch die Adressierungsinformationen der Broker-Instanz (broker.address) und die Sicherheitskonfiguration angegeben werden (security).
Die API bietet einfache Methoden zum Senden (send(Message)) und/oder Empfangen von Nachrichten (receive()) von anderen Agenten. Die Verwendung der API ist für den Cluster-Agenten Cluster-1 in Listing 2 für die Java-Version dargestellt:
//…
//1. instantiation of a connection object
Connection aggreCon = new Con(“aggreCon”);
//…
//2. create a MessageObject
Message request = new Message(“Hello”);
//3. reliably send message to the aggregator
aggregatorCon.send(msgObj);
//4. receive all messages from the aggregator
Message[] answers = aggreCon.receive();
Listing 2: Instantiation and usage of a Connection object.
Zunächst wird ein Connection-Objekt instanziiert, das eine Verbindung zu einer bestimmten Broker-Instanz beschreibt, wie dies in der Konfigurationsdatei angegeben ist. Zweitens wird ein Message-Objekt erzeugt. Drittens wird die Nachricht mit der send()-Methode gesendet, die von der API bereitgestellt wird, indem der Adressat der Nachricht angegeben wird. Danach kann der Benutzer sicher sein, dass die Nachricht zuverlässig an den Empfänger zugestellt wird. Der Aufruf der receive()-Funktionen ruft alle neuen Nachrichten der entsprechenden Kategorie (topic.in) ab.
Smart Grid: Ende-zu-Ende-Verschlüsselung
Zwar ist der Datenaustausch zwischen den Datenquellen bzw. Konsumenten und dem Kafka-Broker über TLS verschlüsselt, trotzdem besteht noch keine echte Ende-zu-Ende-Verschlüsselung zwischen Datenquellen und Datenkonsumenten. Dies bedeutet insbesondere, dass sowohl Datenquellen als auch Konsumenten auf die Unversehrtheit des Brokers vertrauen müssen. Diese Voraussetzung erscheint jedoch besonders in hoch skalierten Umgebungen mit vielen Teilnehmern als kaum annehmbar.
Um hier Abhilfe zu schaffen wurde eine zweite Sicherheitsschicht eingeführt, mit der Anwendungsdaten zusätzlich per asymmetrischem Verschlüsselungsverfahren gesichert werden. Grundsätzlich werden dabei die Anwendungsdaten von der Datenquelle mit dem öffentlichen Schlüssel des adressierten Konsumenten verschlüsselt und können ausschließlich von diesem entschlüsselt werden. Obwohl das Prinzip einfach erscheint, ergeben sich einige domänenspezifischen Besonderheiten die hierbei berücksichtigt werden müssen.
Zunächst ist, wie allgemein bei asymmetrischen Verschlüsselungsverfahren, das Schlüsselmanagement nicht einfach zu handeln – insbesondere bei einer großen Anzahl an Teilnehmern. Die notwendigen Schlüssel müssen vor der Verwendung sicher verteilt werden und ggf. regelmäßig nach Ablauf deren Gültigkeit ausgetauscht werden. Weiterhin wird eine Lösung benötigt, um Gruppenkommunikation effizient abbilden zu können. Prinzipiell sollte es möglich sein, dass mehrere Konsumenten einer Gruppe die verschlüsselten Nachrichten einer Quelle empfangen kann. Jedoch sollten private Schlüssel aus nachvollziehbaren Gründen nicht von mehreren Agenten geteilt werden.
Beide Aspekte werden von der entwickelten Lösung berücksichtigt. Für das Schlüsselmanagement wurde ein weitgehend automatisierter Prozess für die initiale Schlüsselverteilung und den Schlüsselaustausch definiert. Zunächst wird bei Erstellung eines neuen Agenten ein Schlüsselpaar generiert. Der öffentliche Schlüssel wird anschließend an den Betreiber der Broker-Instanz übermittelt. Dieser veröffentlicht diesen in einem öffentlichen Schlüsselverzeichnis. Damit kann der Schlüssel von Kommunikationspartnern empfangen werden. Der öffentliche Schlüssel kann über diesen Weg auch zur Laufzeit ausgetauscht werden.
Um Gruppenkommunikation abzubilden, muss letztlich jede Nachricht für jeden Empfänger separat mit dem jeweiligen privaten Schlüsseln gesichert und versendet werden. Um jedoch von der Effizienz des Kafka-Brokers zu profitieren, werden die Nutzdaten für jeden Empfänger dupliziert und mit dessen öffentlichen Schlüssel gesichert. Anschließend werden die gesammelten und verschlüsselten Nutzdaten zu einer Einzelnachricht zusammengefasst und über den Broker veröffentlicht. Aus dieser Einzelnachricht extrahiert jeder Konsument sein persönliches Nachrichtenduplikat und entschlüsselt dieses mit dem privaten Schlüssel. Potenziell besteht bei diesem Vorgehen aber die Möglichkeit das Nachrichten, je nach Anzahl der Empfänger und Größe der Einzelnachricht sehr groß werden. Allgemein wird aktuell aber davon ausgegangen, dass im wesentlichen Binär kodierte Statusinformationen sowie Mess- und Preisinformationen übertragen werden, deren Volumen als gering eingeschätzt wird.
Die vorgestellte Messaging Lösung fand im EU-Forschungsprojekt Callia ihren prototypischen Einsatz. Das System wurde für die Kommunikation zwischen technischen Anlagen, Aggregatoren, Netzbetreibern sowie dem zentralen Flexibilitätsmarkt verwendet. Im Rahmen der Evaluierung des Gesamtsystems wurde gezeigt, dass die Messaging Lösung mit einer Vielzahl von Kommunikationstechnologien wie Ethernet, WiFi, LTE, oder Powerline Communication (PLC) problemlos funktioniert.










